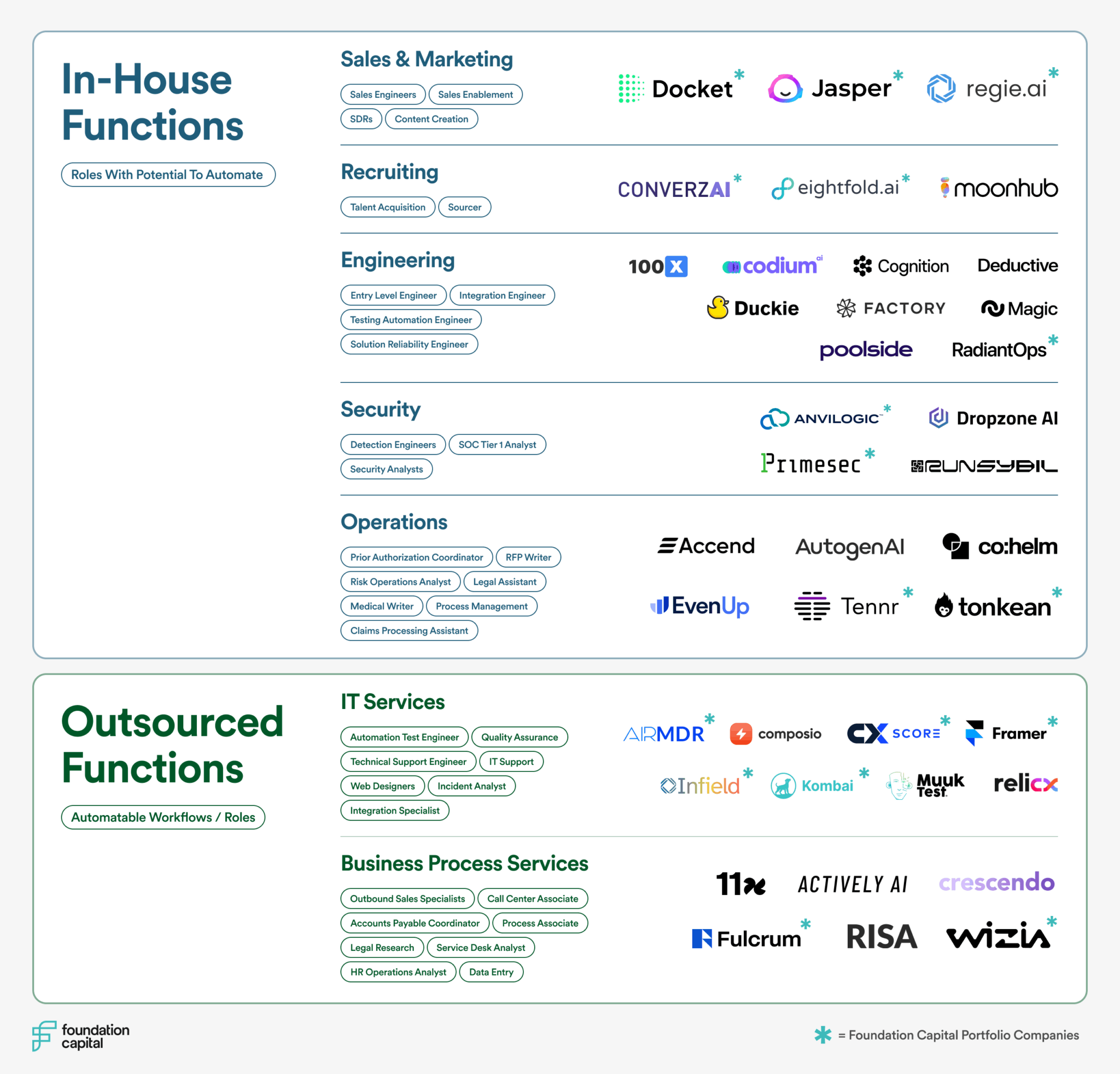
在采访中,Meta的CEO扎克伯格与海外媒体人Dwarkesh Patel就AI技术、Llama模型、Meta AI、以及元宇宙等话题进行了深入的探讨。
首先,扎克伯格介绍了Meta新发布的Llama 3模型,该模型包含80亿参数、700亿参数和4050亿参数三个版本,这些模型将推动Meta AI的发展。Meta AI结合了Google和Bing的实时知识检索功能,并在辅助功能、VR中得到应用,将在未来几个月内推出更多新功能。扎克伯格特别强调了开源对于社区和创新的贡献,并讨论了AI能力的质变可能带来的开源风险。
扎克伯格还提到了Llama 4模型的可能性、在定制芯片上训练Llama模型的计…
过去几十年的自动化主要关注于提高效率,即机器帮助人类加快完成各种任务。当前十年,借助人工智能(AI)的推动,效率将实现飞跃性的进步,同时也会更加复杂。过去,软件仅仅是数字化和增强了人类的工作与服务,但在2.0版本的自动化中,机器人将成为“大脑”。
人工智能公司正在引领从“软件即服务(SaaS)”向“服务即软件”的转型,颠覆了SaaS的核心理念。在软件业务中,公司可能会出售对其平台或工具的访问权,但客户仍需使用这些工具来实现期望的结果。而在服务业务中,实现期望结果的责任则落在提供服务的公司身上。例如,不再提供QuickBooks软件,而是提供由AI会计师执行的税务服务。这一变化的积极面是巨大的…
Stability AI 开发者平台 API 现已推出 Stable Diffusion 3 和 Stable Diffusion 3 Turbo 两款新模型。为了提供这些模型,Stability AI 与市场中最快速、最可靠的 API 平台 Fireworks AI 合作。Stable Diffusion 3 模型在其研究论文中表明,基于人类偏好评估,在排版和提示遵循度方面,其性能等同于甚至超过了其他先进文本到图像生成系统,如 DALL-E 3 和 Midjourney v6。
新款模型采用了多模态扩散变换器(Multimodal Diffusion Transformer,MMDiT)架…
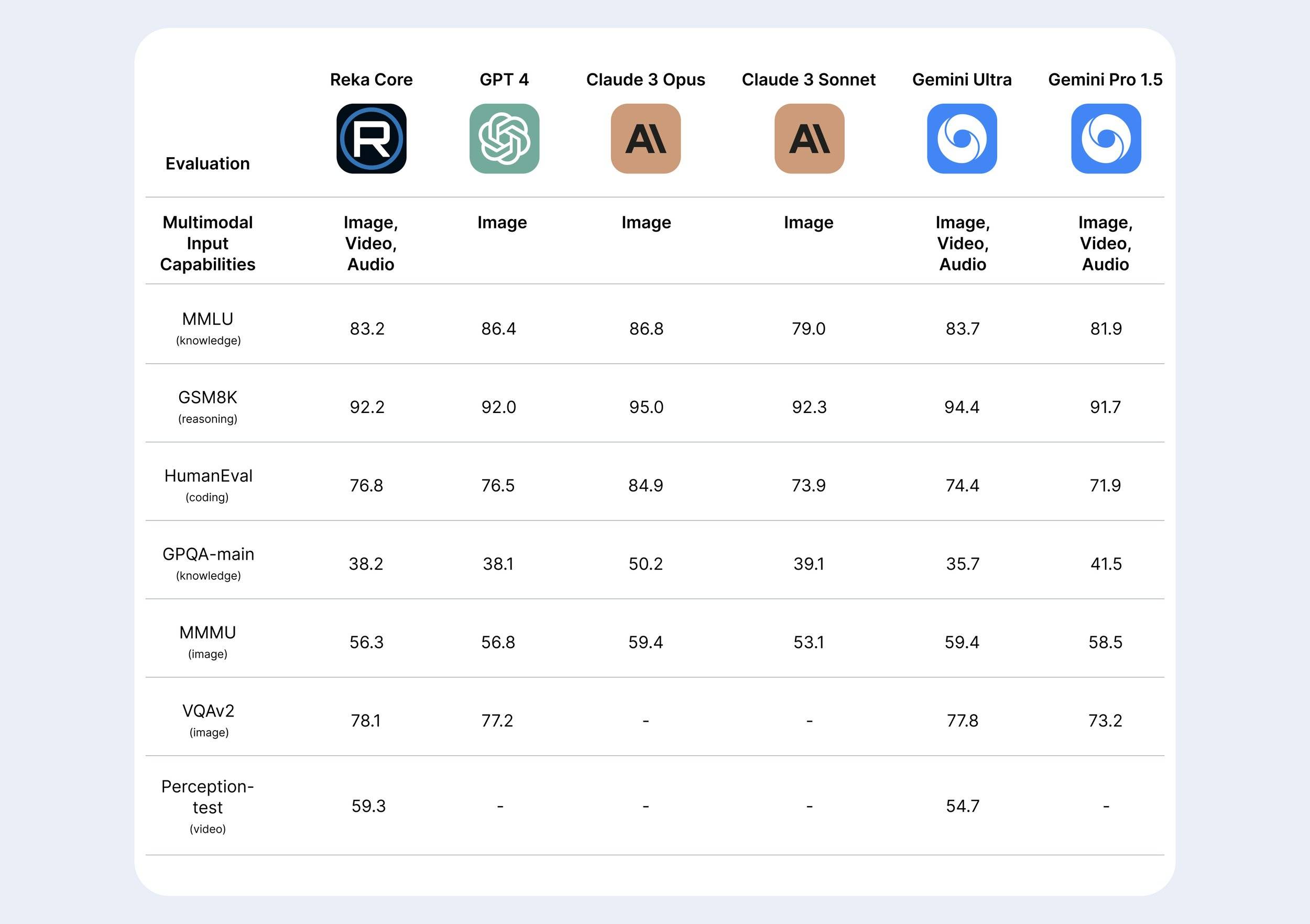
Reka公司推出了迄今为止最大和功能最强大的模型——Reka Core。这是一款行业领先的多模态语言模型,与OpenAI、Anthropic和Google等业内领先的模型相媲美。Reka Core在几个月的时间内,使用数千个GPU从零开始高效训练而成。
性能亮点包括:Reka Core在多模态人类评估中的表现超过了Claude-3 Opus,在视频任务中超过了Gemini Ultra,在语言任务上则与其他前沿模型在公认的基准测试中具有竞争力。此外,Reka Core在MMMU上与GPT-4V相当,提供了出色的性价比。
Reka Core具备以下能力:
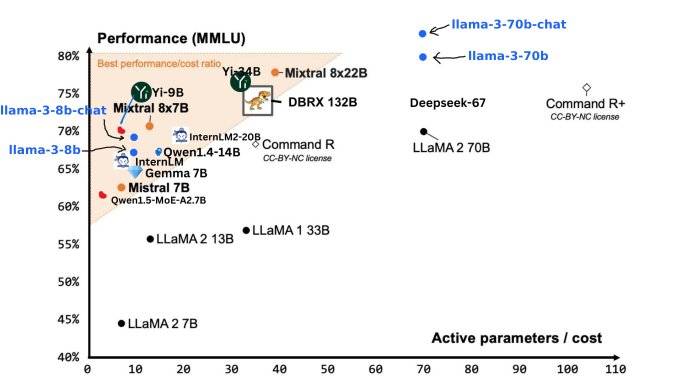
近期,Meta发布了两款新的大型语言模型,分别为8B(80亿参数)和70B(700亿参数)的版本。这些模型带来了新功能,显著提升了推理能力,并在行业基准测试中展示了领先性能。8B参数模型在评测中超过了Gemma-7B和Mistral-7B版本,而Llama 3 70B版本同样在许多评测指标上超越了Gemini 1.5 Pro和Claude 3 Sonnet。
Meta计划在未来几个月内推出更多新功能,包括更长的上下文窗口、更多的模型尺寸选择以及更强大的性能。同时,Meta还将分享Llama 3的研究论文。此外,Meta AI已经正式发布,并将在Instagram、WhatsApp、Messe…
2022年底,ChatGPT的推出标志着大语言模型技术的显著进步,这一技术的发展历经了统计语言模型、神经网络语言模型、预训练语言模型等阶段。OpenAI公司在这一领域扮演了重要角色,推出了引领技术变革的GPT系列模型。尽管GPT-3之后的技术细节不甚透明,但科研人员对于探索大语言模型的复杂性和挑战充满热情。大模型训练的难度在于其所需资源多、参数众多、组件复杂,以及缺少第一手经验的困难。
尽管面临挑战,学术界和工业界对于开放和共享的认识在不断增强,这有助于推动大模型技术的透明化。当前,大模型技术的研发主要源自工业界,并且随着时间的推移,这一趋势可能更为明显。对于科研人员而言,接触技术核心并理解…
在2018年,Dario Amodei 还在 OpenAI 工作时,他开始探索随着数据量的增加,人工智能系统会经历怎样的变化。他发现,AI的能力并非线性增长,而是以指数级的速度提升。起初增长缓慢,随后迅速增加,形成了所谓的“曲棍球杆效应”。如今,Amodei 已经成为他的AI公司 Anthropic 的CEO,其公司推出的 Claude 3 AI 模型被认为是目前市场上最强大的。Amodei 认为AI正遵循规模法则,沿着指数增长的曲线前进,我们正处于这一曲线的快速上升阶段。
Amodei 在与AI开发者交流时发现,之前认为遥不可及的科技愿景在两年内就有可能实现。他在节目中分享了对未来技术突破…
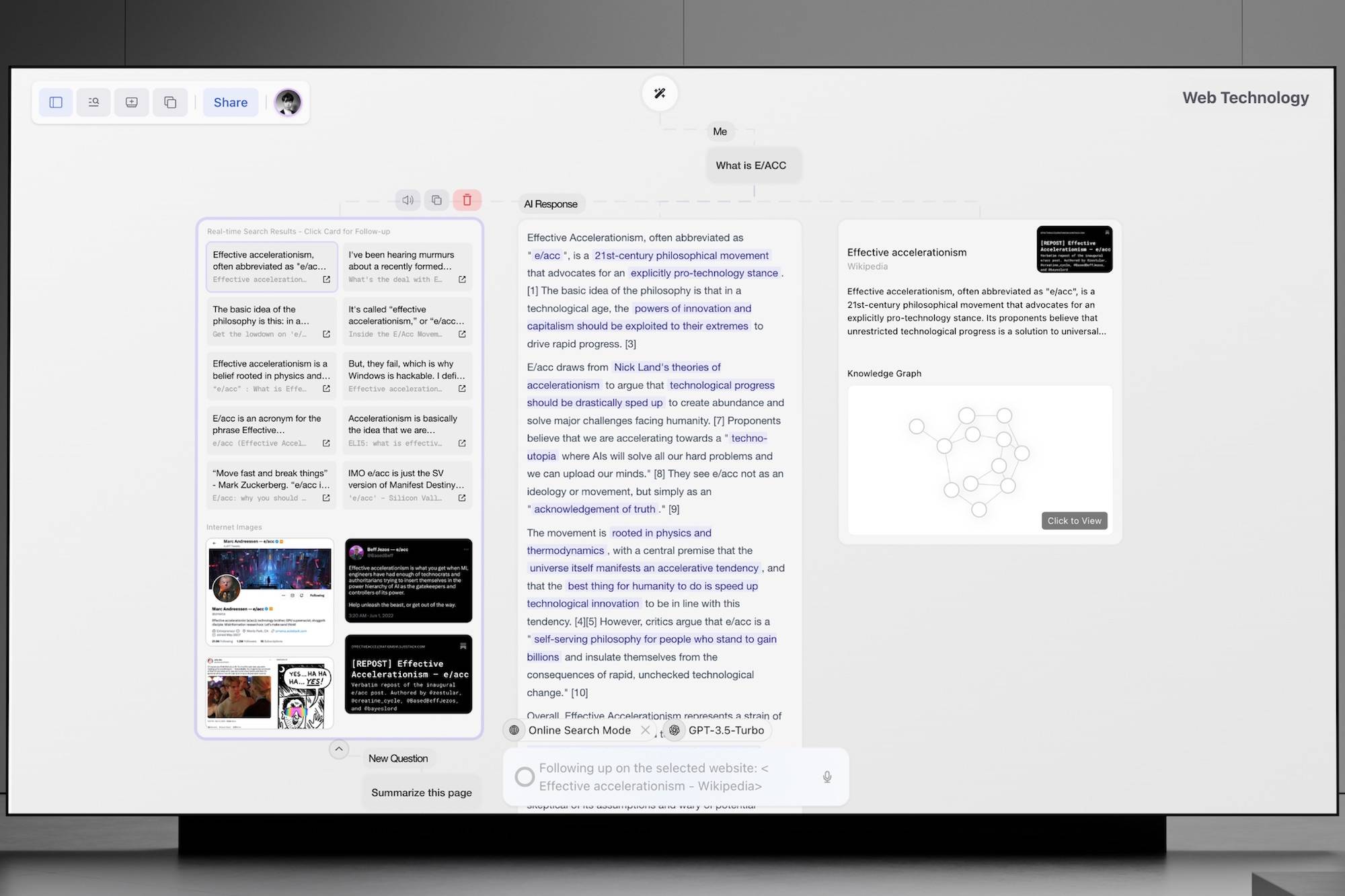
Flowith是一款创新的AI生产力工具,它在过去十个月中被开发以提升用户在创造内容时的效率,并帮助用户更容易进入心流状态。这款工具的核心特点包括:
基于画布的交互:与传统的聊天式界面不同,Flowith采用类似Figma的画布交互方式,使用户能够更高效地进行内容生产活动,如反复生成文案和代码。
多人协作与社区分享:Flowith允许用户实时在画布上与他人协作生成内容,或将创作分享给好友或社区,直接在画布上进行多人讨论。
生成式UI:在自动模式下,AI会根据用户的输入自动调整使用的AI模型和用户界面,以降低使用门槛。
**高性价比的订阅方…
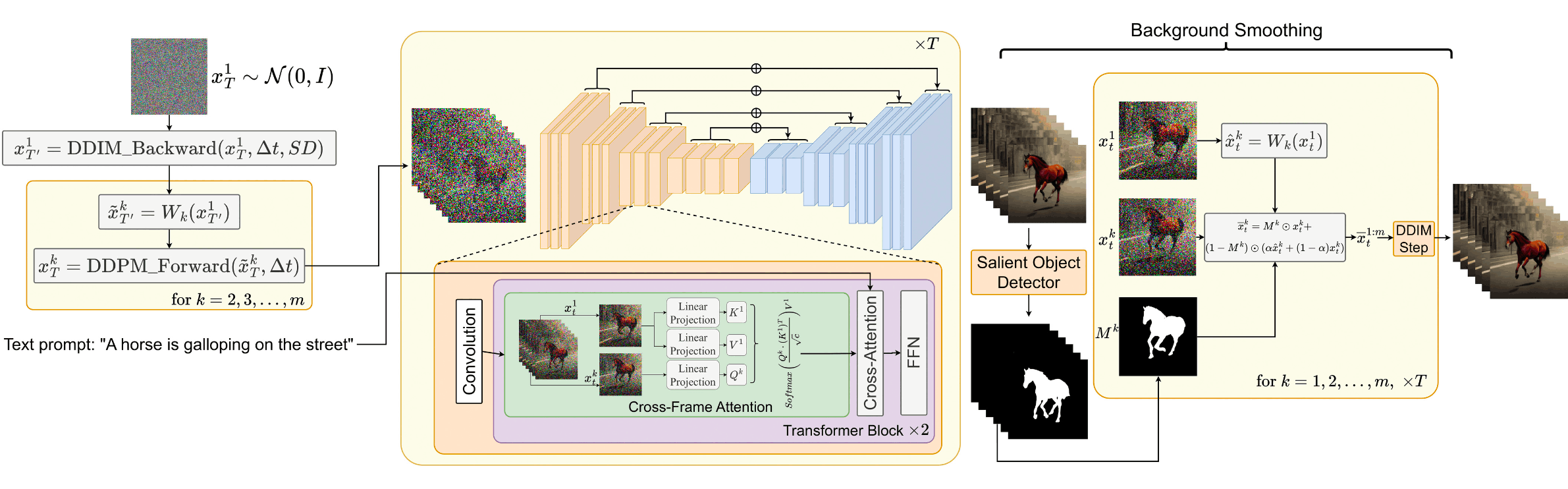
文章主要介绍了视频生成建模的各个关键技术与算法原理。首先,文章探讨了扩散模型在图像合成领域的成功应用,并指出当前研究正尝试将其扩展至更具挑战性的视频生成任务。视频生成不仅要在空间维度上合成图像,还需在时间维度上保持帧与帧之间的连续性和一致性,这意味着模型需要能够处理时序信息以及更多的世界知识。此外,与图像数据相比,高质量的文本-视频配对数据更难获得,这也增加了建模难度。
为了在时间维度上生成视频,研究者提出了一种基本方法:在视频帧上添加高斯噪声,然后通过学习逆过程来去除噪声,从而生成清晰的视频内容。文中提到,为了生成视频帧,可以使用DDIM(Denoising Diffusion Impli…
这段文字描述了一种基于潜在扩散模型(LDM)的网络架构,用于一个新的由服装驱动的图像生成任务。该任务的目标是生成穿着目标服装的定制化角色图像,同时使用多样化的文本提示。在这个过程中,图像的可控性非常关键,尤其是要保留服装的细节并忠实于文本提示。为了实现这一点,研究者们引入了一种服装提取器来捕捉详细的服装特征,并通过自注意力融合技术将这些特征整合到预训练的LDM中,以确保目标角色上的服装细节保持不变。同时,他们利用联合分类器自由引导技术来平衡服装特征和文本提示对生成结果的控制。
此外,所提出的服装提取器是一个插件模块,适用于各种微调后的LDM,并且可以与ControlNet和IP-Adapte…